You may have noticed that even strong visuals struggle to hold attention once platforms prioritize motion. A single image, no matter how well designed, often feels incomplete when compared to dynamic content. This is where tools like Image to Video AI begin to matter—not as novelty generators, but as a shift in how visual ideas are expressed.
The gap is not about creativity. It is about format. Static content cannot compete with motion-driven feeds, and traditional video production remains too slow for everyday creators. The interesting question is not whether images can move, but whether they can move in a way that still preserves their original identity.
This is where image-to-video systems start to feel less like tools and more like translation layers between intention and motion.
Why Motion Is Becoming a Structural Requirement Online
The shift toward motion is not accidental. Platforms increasingly reward:
- Continuous engagement
- Loopable content
- Emotional pacing
- Visual rhythm
A still image delivers a single moment. A video delivers time.
How Time Changes Perception of Visual Content
Once motion is introduced, several things change:
- Attention duration increases
- Emotional interpretation deepens
- Narrative becomes possible
- Visual hierarchy becomes dynamic
This is why creators are no longer asking “what should I design,” but rather:
- What should move
- How should it feel
- Where should attention go next
Why Traditional Video Tools Are Not the Answer
Despite this shift, most video tools still assume:
- Timeline editing
- Manual keyframes
- Complex layerin
For someone starting with a single image, this is excessive.
The emerging alternative is simpler:
- Start with a visual
- Describe motion
- Let the system interpret
How Image-to-Video Systems Actually Work
At a functional level, platforms like image2video.ai follow a relatively consistent structure.
Image As Structural Anchor
The uploaded image defines:
- Composition
- Subject identity
- Lighting baseline
- Visual constraint
The system does not invent from scratch. It extends what already exists.
Prompt As Motion Instruction
The text prompt determines:
- Camera movement
- Subject behavior
- Scene transformation
- Emotional tone
In practice, this means the same image can produce entirely different outputs depending on how it is described.
Model As Temporal Generator
The underlying model fills in what the image lacks:
- Intermediate frames
- Motion continuity
- Visual transitions
- Depth interpretation
In my testing, the results are not always perfectly predictable, but they tend to follow the direction of the prompt rather than ignore it.
What The Actual Workflow Looks Like
The platform itself keeps the process intentionally minimal.
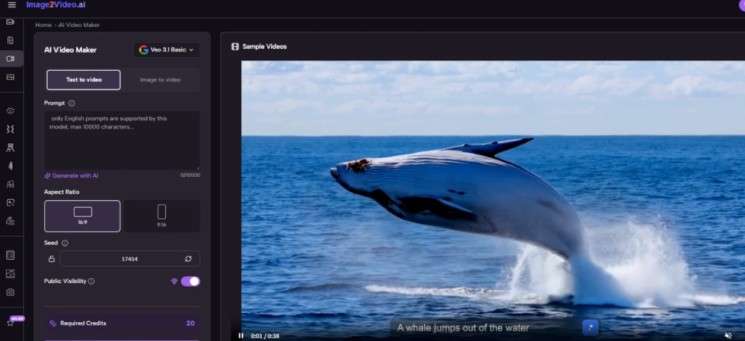
Step 1 Upload A Static Image As Input
You begin by uploading a JPEG or PNG image. This serves as the base visual that the system will animate.
Step 2 Describe Motion Using Text Prompts
You then define how the image should evolve. This includes:
- Movement (e.g. turning, walking, flowing)
- Camera direction (zoom, pan, tilt)
- Atmosphere (cinematic, calm, dramatic)
Step 3 Generate And Review The Video Output
After processing—typically a few minutes—the system produces a video that reflects both the original image and the prompt instructions.
This workflow removes the need for timelines, editing layers, or manual animation.
Where Camera Motion Becomes The Real Differentiator
One aspect that stands out is how camera movement is treated.
Types Of Motion You Can Control
The system allows prompts that simulate:
- Pan (horizontal movement)
- Zoom (forward/backward motion)
- Tilt (vertical angle shift)
- Rotation (subtle perspective change
These are not exact manual controls, but rather interpreted instructions.
Why Camera Language Matters More Than Animation
Interestingly, in many outputs:
- Camera movement carries more emotional weight than subject motion
- Subtle zooms can feel more cinematic than large movements
- Perspective shifts add depth even to flat image
This suggests that the system is not just animating objects—it is approximating cinematography.
How Template-Based Effects Change User Behavior
The platform also provides preset scenarios such as:
- Dance sequences
- Interaction scenes (hug, fight, etc.)
- Stylized motion effects
These templates reduce decision fatigue.
Instead of asking “what should happen,” users choose:
- A predefined interaction
- A motion style
- A visual outcome category
This changes the workflow from creation to selection plus refinement.
Comparing This Approach With Traditional Video Creation
To understand its role, it helps to compare it with other methods.
| Aspect | Image-to-Video Workflow | Traditional Video Editing |
| Starting point | Single image | Raw video clips |
| Control method | Text prompts | Timeline + keyframes |
| Speed | Minutes per output | Hours or days |
| Skill requirement | Low to moderate | High |
| Iteration style | Regenerate outputs | Edit layers manually |
| Predictability | Medium | High |
The key trade-off is clear:
- You gain speed and accessibility
- You lose precise control
Where This Type Of Tool Actually Fits
From observation, the strongest use cases are not cinematic production, but:
Content Prototyping
- Testing ideas quickly
- Generating variations
- Exploring visual directions
Social Media Adaptation
- Converting static posts into short videos
- Increasing engagement without redesigning asset
Concept Visualization
- Turning sketches or references into motion
- Communicating ideas more clearly
Lightweight Storytelling
- Adding narrative hints to otherwise static images
- Creating emotional progression
Why Output Quality Still Depends On Input Thinking
Despite automation, results are not fully automatic.
Prompt Sensitivity
Small wording changes can lead to:
- Different motion intensity
- Different pacing
- Different interpretations of the same scene
Image Constraints
The system cannot fully override:
- Poor composition
- Low resolution
- Ambiguous subjects
Iteration Is Still Required
In most cases:
- First output is usable but not optimal
- Refinement comes from adjusting prompts
- Multiple generations are common
What This Means For The Future Of Visual Creation
Tools like this suggest a broader shift:
- From manual construction to guided generation
- From technical execution to conceptual direction
- From static assets to dynamic-first thinking
The interesting part is not that images can move. It is that creators no longer need to think in timelines to create motion.
Where The Second Layer Of Value Emerges
As workflows mature, another layer becomes relevant.
Later in the process, tools such as Photo to Video become less about experimentation and more about refinement—turning selected visuals into consistent, repeatable motion outputs that align with a specific style or brand direction.
This is where the system shifts from being a creative toy to a production component.
Limitations That Are Easy To Overlook
It is important to acknowledge where the system still struggles.
Control Precision Is Limited
You cannot:
- Define exact motion paths
- Control frame-by-frame timing
- Guarantee identical outputs

Results Can Vary Between Generations
Even with the same prompt:
- Outputs may differ slightly
- Motion smoothness can vary
- Some artifacts may appear
Complex Scenes Are Harder To Maintain
Scenes with:
- Multiple subjects
- Detailed interactions
- Fast motion
tend to be less stable.
Why This Still Matters Despite Imperfections
Even with these constraints, the value is not diminished.
Because the goal is not perfection. It is:
- Speed of exploration
- Accessibility of motion
- Expansion of creative option
In that sense, image-to-video tools are not replacing traditional workflows. They are filling a gap that previously had no efficient solution.
And that gap—between static intent and dynamic expression—is where most modern content now lives.